Controlling Disruption
Disruption in Kubernetes
A Pod in Kubernetes may be disrupted for involuntary reasons, e.g. hardware failure, or voluntary reasons, such as when nodes are drained for upgrades.
By default, Agones assumes your game server should never be disrupted voluntarily and configures the Pod appropriately - but this isn’t always the ideal setting. Here we discuss how Agones allows you to control the two most significant sources of voluntary Pod evictions, node upgrades and Cluster Autoscaler, using the eviction API on the GameServer object.
Benefits of Allowing Voluntary Disruption
It’s not always easy to write your game server in a way that allows for disruption, but it can have major benefits:
- Compaction of your cluster using Cluster Autoscaler can lead to considerable cost savings for your infrastructure.
- Allowing automated node upgrades can save you management toil, and lowers the time it takes to patch security vulnerabilites.
Considerations
When discussing game server pod disruption, it’s important to keep two factors in mind:
TERMsignal: Is your game server tolerant of graceful termination? If you wish to support voluntary disruption, your game server must handle theTERMsignal (even if it runs to completion after receivingTERM).- Termination Grace Period: After receiving
TERM, how long does your game server need to run? If you run to completion after receivingTERM, this is equivalent to the session length - if not, you can think of this as the cleanup time. In general, we bucket the grace period into “less than 10 minutes”, “10 minutes to an hour”, and “greater than an hour”. (See below if you are curious about grace period considerations.)
eviction API
The eviction API is specified as part of the GameServerSpec, like:
apiVersion: "agones.dev/v1"
kind: GameServer
metadata:
name: "simple-game-server"
spec:
eviction:
safe: Always
template:
[...]
You can set eviction.safe based on your game server’s tolerance for disruption and session length, based on the following diagram:
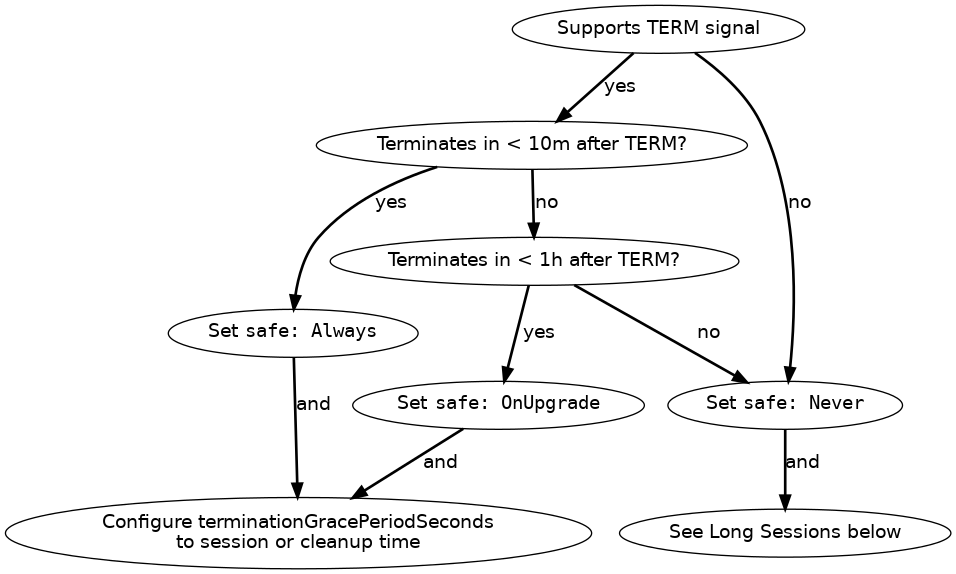
In words:
- Does the game server support
TERMand terminate within ten minutes?- Yes to both: Set
safe: Always, and set terminationGracePeriodSeconds to the session length or cleanup time. - No to either: Does the game server support
TERMand terminate within an hour?- Yes to both: Set
safe: OnUpgrade, and configure terminationGracePeriodSeconds to the session length or cleanup time. - No to either: Set
safe: Never. If your game server does not terminate within an hour, see below.
- Yes to both: Set
- Yes to both: Set
To maintain backward compatibility with Agones prior to the introduction of eviction API, if your game server previously configured the cluster-autoscaler.kubernetes.io/safe-to-evict: true annotation, we assume eviction.safe: Always is intended.
GKE Autopilot supports only Never and Always, not OnUpgrade. However, with Kubernetes 1.27, Autopilot introduces support for extended duration pods that can run for up to 7 days, helping to maintain game server sessions without disruption during this period.
What’s special about ten minutes and one hour?
-
Ten minutes: Cluster Autoscaler respects ten minutes of graceful termination on scale-down. On some cloud products, you can configure
--max-graceful-termination-secto change this, but it is not advised: Cluster Autoscaler is currently only capable of scaling down one node at a time, and larger graceful termination windows slow this down farther (see autoscaler#5079). If the ten minute limit does not apply to you, generally you should choose betweensafe: Always(for sessions less than an hour), or see below. -
One hour: On many cloud products,
PodDisruptionBudgetcan only block node upgrade evictions for a certain period of time - on GKE this is 1h. After that, the PDB is ignored, or the node upgrade fails with an error. ControllingPoddisruption for longer than one hour requires cluster configuration changes outside of Agones - see below.
Considerations for long sessions
Outside of Cluster Autoscaler, the main source of disruption for long sessions is node upgrade. On some cloud products, such as GKE Standard, node upgrades are entirely within your control. On others, such as GKE Autopilot, node upgrade is automatic. Typical node upgrades use an eviction based, rolling recreate strategy, and may not honor PodDisruptionBudget for longer than an hour. See Best Practices for information specific to your cloud product.
Extended Duration Pods in GKE Autopilot (Kubernetes 1.27+)
Starting with Kubernetes 1.27, GKE Autopilot introduces support for extended duration pods, allowing them to run continuously for up to 7 days. This feature is ideal for game servers that need longer operational periods. It helps to minimize disruptions during node upgrades over the 7-day duration.
Implementation / Under the hood
Each option uses a slightly different permutation of:
- the
safe-to-evictannotation to block Cluster Autoscaler based eviction, and - the
agones.dev/safe-to-evictlabel selector to select theagones-gameserver-safe-to-evict-falsePodDisruptionBudget. This blocks Cluster Autoscaler and (for a limited time) disruption from node upgrades.- Note that PDBs do influence pod preemption as well, but it’s not guaranteed.
As a quick reference:
| evictions.safe setting | safe-to-evict pod annotation |
agones.dev/safe-to-evict label |
|---|---|---|
Never (default) |
false |
false (matches PDB) |
OnUpgrade |
false |
true (does not match PDB) |
Always |
true |
true (does not match PDB) |
Further Reading
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.
Last modified July 8, 2026: docs: add Flowtriq to Third Party Libraries and Tools (#4636) (bbb47d5)